开云体育官方网站 机器东谈主具身操作评估新范式来了, 从此告别单一告成率目的


作家先容:刘梦源,北京大学深圳商讨生院商讨员,商讨界限为东谈主类举止见解与机器东谈主技巧学习;盛抵抗,北京大学在读博士商讨生,商讨标的为机器东谈主操作技巧学习要领商讨;王梓懿、李培铭,北京大学在读硕士商讨生,商讨标的为视频见解分析;徐天铭,北京大学在读硕士商讨生,商讨标的为机器东谈主操作技巧学习要领商讨;徐天添,中国科学院深圳先进技能商讨院集成所商讨员,商讨界限为磁控袖珍机器东谈主导航、机器东谈主的协同贬抑等;刘宏,北京大学深圳商讨生院熏陶,商讨界限为议论机视觉与智能机器东谈主、机器学习与智能东谈主机交互。

论文标题:Trustworthy Evaluation of Robotic Manipulation: A New Benchmark and AutoEval Methods
论文推敲:https://arxiv.org/abs/2601.18723
代码推敲: https://github.com/LogSSim/TERM-Bench
跟着 Vision-Action (VA) 和 Vision-Language-Action (VLA) 模子的爆发,机器东谈主效法学习得到了长足跨越。然则,刻下的评估体系却面对着严重的「信任危境」。现存的评估范式主要依赖二元的「告成率(Success Rate)」,这种浅薄的目的笼罩了两个枢纽问题:
推论质地的否认性(Gap 1):相似是「告成」完成任务,模子 A 可能四肢僵硬、陪同剧烈抖动(Jerky Success),而模子 B 则游刃过剩。传统的二元评价无法永诀二者,导致潜在的安全隐患被冷落。
着手的否认性(Gap 2):在一些已有的展示视频中,不仅难以判断四肢是否由果真的自主计营生成,以致难以分辨其是否由东谈主类云尔操作(Teleoperation)「冒充」。
为了措置上述评估信任危境,北大与中科院团队建议了一套完整的措置决策:Eval-Actions 评估基准与 AutoEval 自动化评估架构。该决策旨在从「细粒度四肢质地」和「着手真实性」两个维度,重塑机器东谈主操作的评估步履。
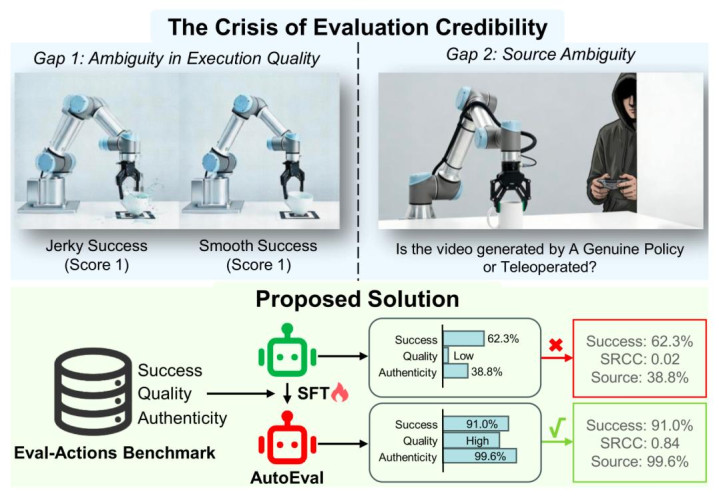
图 1 (上) 评估危境:现存二元目的笼罩了推论质地(如「抖动告成」与「平滑告成」的区别)和着手真实性(难以永诀计营生成与东谈主类遥操作)的否认性。 (下) 措置决策:Eval-Actions 基准与 AutoEval 架构(绿色部分)相联结,填补了这两大空缺,已矣了精确的细粒度质地评估与鲁棒的着手考证,显贵优于传统的通用 VLM(红色部分)。
填补空缺:首个面向评估完整性的 Eval-Actions 基准
表格 1 机器东谈主操作数据集的对比分析。与以模子进修持中枢、追求原始轨迹数据量最大化的数据集不同,Eval-Actions 以标注密度最大化为联想主见,特有的上风在于提供故障场景数据、羼杂轨迹数据源。
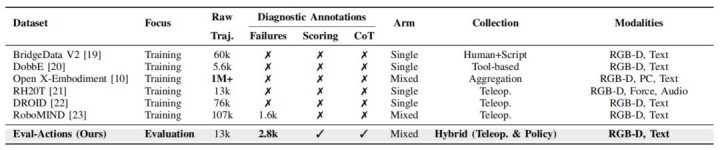
为了冲破现存数据集仅存眷「告成演示」的局限,商讨团队构建了 Eval-Actions 基准。与 Open X-Embodiment 等以进修持目的的数据集不同,Eval-Actions 专为会诊性评估而生。
包含失败场景:数据集不仅包含告成的轨迹,还改进性地引入了约 2.8k 条失败数据。这关于模子学习失实规复和鲁棒的失败检测至关紧迫 。
羼杂着手考证:数据集羼杂了东谈主类遥操作数据与多种计谋(VA 及 VLA 模子)生成的轨迹,为考证「着手真实性」提供了数据基础。
多维监督信号:提供了内行评分(Expert Grading)、排序交流(Rank-Guided)以及念念维链(Chain-of-Thought, CoT)三种档次的瞩目,解救从数值评分到逻辑推理的全场地评估。

图 2 Eval-Actions 基准概览。包含从单臂到双臂的 150 + 任务,并提供细粒度的质地雷达图与 CoT 瞩目。
AutoEval:双引擎入手的自动化评估内行
为了已矣对机器东谈主举止的精确会诊,团队联想了 AutoEval 框架。它并未招揽单一模子,而是针对不同的评估维度,改进性地建议了 AutoEval-S 和 AutoEval-P 两种架构,分别措置「看不清细节」和「胡乱推理」的困难。
1. AutoEval-S:精确捕捉四肢细节
传统的 VLA 模子常常只可处理寥落的枢纽帧,kaiyun sports容易遗漏四肢推论经由中的抖动或停顿。AutoEval-S(Small)引入了时空团聚计谋(Spatio-Temporal Aggregation)。
高频细节压缩:它并莫得浅薄丢弃中间帧,而是将高频的盛开细节「压缩」 进视觉 Token 中,最大化了时分信息的密度。
物理信号校准:辅以盛开学校准信号(Kinematic Calibration Signal),径直哄骗速率和加快度方差等物理数据来校准视觉评估,确保评分精确响应四肢的平滑度与安全性。
2. AutoEval-P:具备逻辑推明智力的「考官」
当需要模子输出念念维链(CoT)进行证及时,传统模子常出现「幻觉」,即推理逻辑与打分不一致(举例嘴上说「四肢无缺」,本色上物体照旧掉了)。AutoEval-P(Plus)引入了组相对计谋优化(GRPO)范式。
强制齐整不二:通过强化学习,AutoEval-P 被进修在生成评分的同期,必须给出逻辑自洽的物理推理。其羼杂奖励函数(Hybrid Reward Function)同期敛迹内容的准确性和面孔的表狂放,灵验摈斥了大模子的推理幻觉。
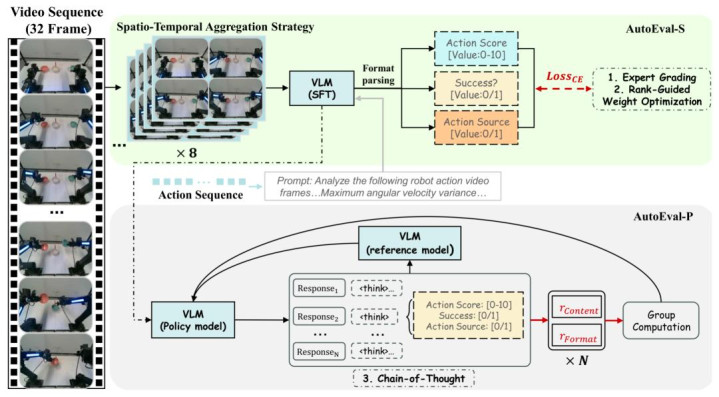
图 3 上分支 (AutoEval-S):专为评分与排序联想。招揽时空团聚计谋将高频盛开细节压缩至视觉 Token,并辅以物理校准信号,精确捕捉四肢中的幽微抖动。下分支 (AutoEval-P):专为念念维链(CoT)推理联想。引入 GRPO 强化学习范式,通过羼杂奖励函数(内容 + 面孔)强制模子生成逻辑自洽的物理推理与评分,灵验措置大模子的「幻觉」问题 。
本质斥逐:树立着实评估新步履
在 Eval-Actions Small (EAS) 子集上的凡俗本质标明,AutoEval 框架在多姿色的上展现出额外性能,全面越过了 InternVL、QwenVL 等通用大模子 。
1. 极高的着手辩别力:让「作秀」无处遁形
AutoEval 粗略以 99.6% 的准确率永诀视频是来自真实的计营生成如故东谈主类遥操作,灵验措置了「着手否认性」问题,为机器东谈主社区提供了一套泰斗的防伪器具。
2. 细粒度评分高度对王人东谈主类
在预料四肢平滑度、安全性和后果的概述质地评分上,AutoEval-S 与东谈主类内行的判断高度一致。
在内行评分(EG)条约下,SRCC 达到 0.81 。
在排序交流(RG)条约下,SRCC 高达 0.84,显贵优于未微调的 InternVL3.5-4B (SRCC ≈ 0.02) 和 QwenVL3-4B。
表格 2 Eval-Actions 基准上的性能对比 在内行评分(EG)、排序交流(RG)及念念维链(CoT)三种条约下,AutoEval 均得到了 SOTA 性能。相等是在 RG 条约下,AutoEval-S 的评分关系性(SRCC)达到 0.84,着手预计准确率高达 99.6%,远超未微调的 InternVL 和 QwenVL 等基线模子。
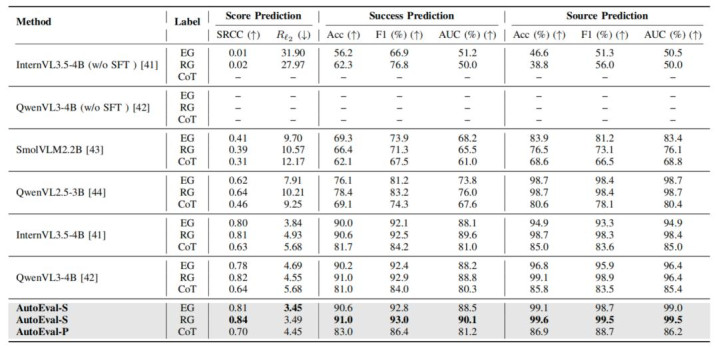

图 4 细粒度四肢质地评估的定性对比
3. 跨构型泛化智力
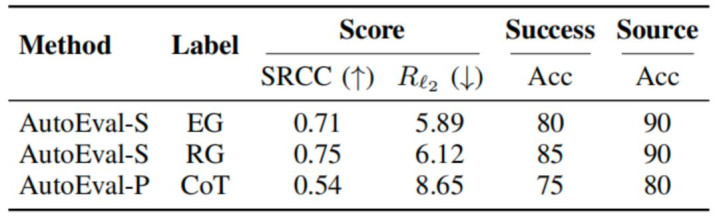
即使在未见过的 Franka 机器东谈主数据上,AutoEval 依然保抓了庄重的评估智力。AutoEval-S 在新形状机器东谈主上仍能达到 0.75 的评分关系性(SRCC)和 90% 的着手预计准确率,展现了强大的跨实体泛化后劲 。
表格 3 AutoEval 在未见构型 Franka 机械臂数据上的泛化本质斥逐
4. 永诀云尔操作和计谋推论视频
号码个数分析:历史上排列三第010期同期奖号中,号码0-9出现个数分别为:号码0开出2个,号码5开出3个,号码7、9开出4个,号码3开出6个,号码4、6开出8个,号码1开出9个,号码2开出10个,号码8开出12个,今年第010期排除号码2。



 开云体育官方网站
开云体育官方网站
 备案号:
备案号: